
How hashmaps work?
Okay, so lets start with what hashmaps are? Hashmaps or hashtables are known by different names in different languages.
- Python has dict/dictionaries
- Ruby calls it Hash
- Java has hashmap
- C++ has unordered_map
- Even Javascript has maps, which is how basically objects are implemented in javascript. (just look at JSON)
What the last point says about hashmaps being used to implement objects in Javascript is also true in case of Python, Ruby and a few others.
So hashmaps/dicts/hashtables whatever you want to call them are basically key-value storage data structures. You pass in a value identified by a key, and you can get back the same value with that key - simple as that.
So lets try and get hands on with how it looks in code.
| |
That gives us the list of basic operations on a dict:
- insert
- fetch
- delete
The same can be shown with Javascript:
| |
Enough of examples now, lets get to see how these things work on the inside
So, we will be implementing a simple hashtable in Golang. If you haven’t heard or written code in Go, and are skeptical about understanding the code that follows - worry not, Go has a syntax very similar to C and Javascript. And if you can code (in a language), you’re gonna do just fine!
The building blocks
This image taken from wikipedia shows the basic structure of our hashtable. This will help us understand and break down the problem at hand better:
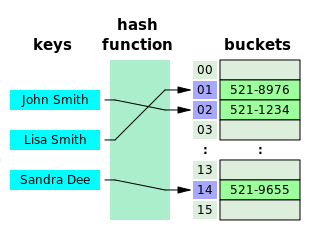
To summarize, we have:
- the hash function
- the linear array that the hash function maps to
- and the actual data nodes that hold our key-value pairs
The array
So lets start with our linear array to begin with. So we basically need a statically allocated array of some size n. This will be the array holding the pointer to our actual key value pairs. This is how our basic array will look like:
| |
Let us code this up in Go. To have a basic array inside our hashmap data type. This is going to be fairly easy to achieve.
| |
The above code is explained below:
We declare the current file as main package with package main.
We import a package called “fmt”, we’ll later use it to print things to terminal.
We declare a constant variable MAP_SIZE with value 50 . This will be the size of our linear array.
For the sake of simplicity, we are assuming that we just have a fixed size array that we use for implementing our hashmap, and we don’t take resizing into account. Actual implementations do account for these things - which will be covered in a future blog post. For more info refer here.
Next we create a function NewDict that creates this array for us and returns a pointer to it.
This completes our bare-bones structure for the array itself. But we are presented with the next challenge. Which is, how to represent the key-value pairs that contain our actual data and link it with our array.
Creating the nodes and linking with array
There is one problem in the code presented above — we have created an array of pointer to integer values. Basically the Data []*int on line8. This is wrong because we need to actually not point to integers but to some object that holds our key-value pairs. We don’t know what that object will be yet, but we know that it needs at least 2 fields — key and value. So lets go ahead and create this new object’s structure in our code.
We add the following lines:
| |
We create a structure to hold our key-value pairs and a pointer to a Node type. We will need this pointer later on in order to deal with hash conflicts. More on this later, for now just let it sit around there.
Now since we want every index of our array to point to these Node type, we should change the type of our data array.
| |
So at the end of these changes, this is how our code should look like:
| |
If you run this program right now, you should see something like this:
| |
We have our hashmap object consisting of an array of 50 pointers each pointing to <nil> which is something equivalent to:
NULLin C.nullin Java.Nonein Python.undefinedin Javascript.
This is just as expected, we haven’t inserted any value in the hash table so all pointers are pointing to null/nil . Next we have to think about inserting objects into our hashmap.
Before we could even reach that, we need to find a way to convert our keys to corresponding indexes on the array.
A typical implementation of hash maps relies on a good hash function. The job of a hash function is to convert the value passed to it (in our current case, a string) and return an integer value representing an index on the array. And this integer value has to be the same every time.
This means that if hash("hello") gives me 966170508347869221, then every time I pass "hello" I should get the same 966170508347869221 as a return value.
You can test the above mentioned code in the Python interpreter. Python has a builtin function
hashthat will return the hash value.
But we cannot have index 966170508347869221 on our array. Currently we have only indexes 1-49 available. Hence we need to somehow bring it down to this range.
Modulo to the rescue
The simplest solution to this problem is using the modulo (%) operator. This operator gives us the remainder of the division performed. That is, if
966170508347869221 / 50 = 19323410166957384 + 21
then 966170508347869221 % 50 = 21. The remainder.
But with this, we have another problem, there will be keys which will be mapped to the same index, hence we’ll get a hash collision.
From this point on, we have 3 problems to solve at hand:
- How do you implement the hash function.
- Make the hash value fall in range of our array.
- How to manage hash collisions.
Let’s start with the hash generation function first
Choosing a hash algorithm
Wikipedia has a list of many hash_functions. Which you can refer here https://en.wikipedia.org/wiki/List_of_hash_functions
For our purpose, we’ll use a Jenkins hash function. It is a hash function that produces 32-bit hashes. The wikipedia article also has the implementation of the algorithm in C. We’ll just translate that to our go code.
| |
The above function uses a named-return — see https://golang.org/doc/effective_go.html#named-results
With this in place our code should look like this:
| |
Mapping the hash to our array
Now that we have found our way to convert our keys to the hash value, we now need to make sure that this value falls within out array. For this we implement a getIndex function:
| |
With this in place, we have taken care of 2 of our 3 problem statements. The 3rd problem - managing collisions will be taken care of at a later stage. First we now need to focus on inserting the key-value pairs in our array. Lets write a function for that.
Insertion
The following function uses a receiver, which are a powerful feature of go.
| |
The code is mostly self explanatory, but we’ll briefly go over it anyway.
We first call getIndex with the key, which in-turns calls the hash function internally. This gives us the index on our array where we can store that key-value pair.
Next we check if the index is empty, if yes - then we simply store the K-V Pair there. This would look something like this:
| |
The above denotes the if part of our code - when there are no collisions. The else part of our code handles the collision.
There are a few different ways of handling collisions in hashmaps:
- Separate chaining with linked lists
- Open addressing
- Double Hashing
The current code in the else block handles collisions with the Separate chaining with linked lists technique.
The linked list technique will result in a data structure very similar to the following image:
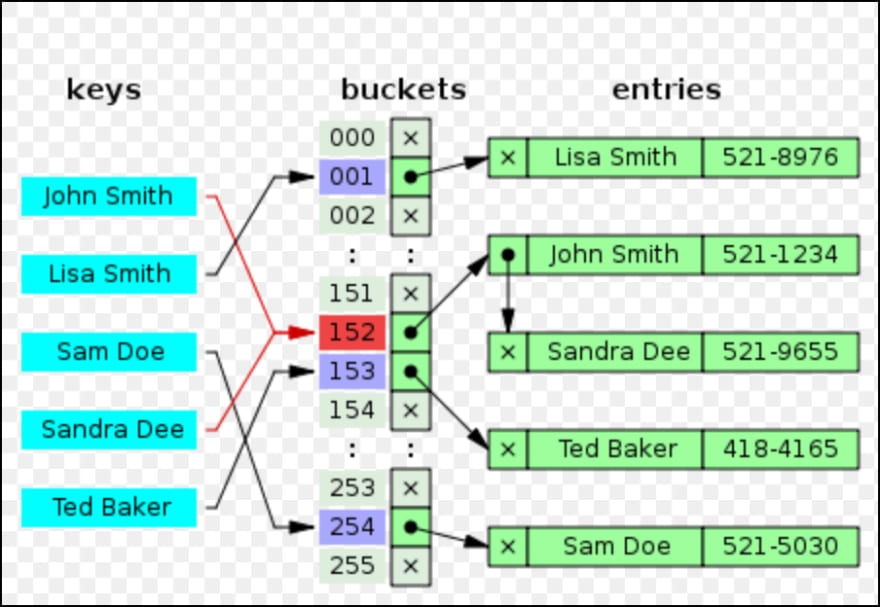
The two keys mapping to the same index - hence resulting in a collision are shown in red.
Next we’ll talk about retrieving the value back from our hashtable
Fetch
The next basic operation on hashmaps that we are going to look at is Fetch. Fetch is fairly simple and identical to insert - we pass our key as input to the hash function and get a hash value, which is then mapped to our array using the getIndex function.
We can then have 3 possible outcomes:
- We check if the
keyon that index is matching the we are looking for - if yes, then we have our match. - If the key does not match, we check if its next value is not
nil- basically checking for collision and find that element in the separate chained linked list - If both of the above conditions fail, we concur that the requested key does not exist in our hashtable.
The code implementing the above explanation is shown below:
| |
The above code uses golang’s multiple return values feature.
With this in place, we’ll write the main function and test these operations that we have implemented.
| |
Also lets add a convenience function that allows us to print our hashmap in the desired format.
| |
This overrides the default print output for our defined HashMap type.
The above method is just a convenience method used for printing the entire hashmap in a pretty format. It is in no way required for proper functioning of the data structure
To sum it up, here’s our final code:
| |
Running
On running the above code, we get the following output:
| |
- The first line is the value of our key
name. - The output from 2nd line onwards is basically our custom-coded pretty-print function that outputs our entire hashmap.
If you’re interested in running/experimenting with this code, please feel free to fork the following repl. You can also play around on this webpage interactively.
Our current implementation only supports strings as keys. In the next blog post we’ll talk about how we can make this a more generic implementation.
This post was originally published on my blog at ishankhare.com